大型語言模型(LLM, Large Language Models)已經改變了我們與人工智慧(AI)互動的方式,並在聊天機器人、內容創作、專家系統等領域發揮關鍵作用。然而,通用型 LLM 雖然用途廣泛,但對於企業內部的特定需求來說,可能無法精確理解行業專業術語與內部文件。因此,訓練 LLM 來適應企業特定領域的需求變得至關重要。
想要打造專屬於自己領域的 LLM 模型嗎?或是在糾結要選擇微調還是 RAG?本文將深入分析這兩種技術的優劣,並提供完整的實作指南,幫助您做出最適合的技術選擇。
為什麼企業需要專屬的 LLM?
- 提高準確性:讓 AI 更好地理解企業內部術語與知識。
- 降低錯誤率:減少因通用模型理解錯誤導致的業務風險。
- 強化資料安全:確保企業機密資料不會被外部 LLM 訓練使用。
- 提升用戶體驗:提供更專業、即時且精確的回答。
訓練 LLM 可分為三個主要階段:
- 自監督學習(Self-supervised Learning):透過大量未標註的數據學習語言結構。
- 監督學習(Supervised Learning):透過人工標註的資料進一步優化模型,使其能夠更準確地完成特定任務。
- 強化學習(Reinforcement Learning):透過人類反饋來微調模型行為,提升回應的品質與安全性。
此外,企業在訓練 LLM 時可以採取兩種方法:
- 微調(Fine-tuning):在預訓練模型的基礎上,進一步訓練以適應特定領域。
- 檢索增強生成(RAG, Retrieval-Augmented Generation):結合知識檢索來增強模型的回應能力。
本篇文章將詳細介紹如何透過這些方法訓練 LLM,並分享具體的案例應用。
Insights
- 企業導入 LLM 的核心價值在於三方面:通過深度理解專業術語提升準確性、強化數據安全性、以及優化用戶體驗,這也解釋了為什麼通用型 LLM 無法完全滿足企業需求。
- LLM 訓練的完整方法論需要結合三個階段(自監督、監督和強化學習)和兩種技術(微調和 RAG),並根據業務場景靈活選擇,例如法規諮詢適合 RAG,而專業診斷則適合微調。
- 企業成功應用 LLM 的關鍵不在於技術選擇,而在於是否能夠清晰定義目標、準備高質量數據、持續監控效果,並採取適當的混合策略來平衡各種需求,企業若能將 LLM 與動態知識庫整合,將在等領域取得競爭優勢,並有效降低決策風險。
訓練 LLM 的主要步驟
1. 自監督學習(Self-supervised Learning)
這是 LLM 訓練的第一個階段,主要透過大量未標註文本數據學習語言結構與詞彙關係。例如,模型會學習如何預測句子中的下一個單詞或填補缺失的詞彙。這個過程允許模型建立強大的語言理解能力,並且由於數據是自動生成的,因此可以利用大規模文本來進行訓練。
2. 監督學習(Supervised Learning)
在這個階段,模型透過標註數據進行微調,使其能夠理解指令並執行特定任務,例如摘要生成、問答、情緒分析等。
- 訓練方法:
- 使用人工標註數據來建立高品質的訓練集。
- 使用範例來幫助模型學習更好的輸出格式。
- 工具推薦:Hugging Face Transformers、PyTorch、TensorFlow。
3. 強化學習(Reinforcement Learning)
透過人類反饋強化學習(RLHF),對模型進行微調,使其能夠生成更符合預期的回應。
- 訓練方法:
- 透過人工標註來評分模型的回應。
- 訓練獎勵模型來指導 LLM 生成更符合人類偏好的輸出。
- 應用場景:
- 降低模型生成不當內容的機率。
- 提升語言流暢性與可讀性。

應用 LLM 訓練於企業內部專家系統
1. 微調(Fine-tuning)
微調是最直接的方法,適用於需要高度專業知識的場景,如:
- 企業內部專家系統
- 醫療診斷
- 法律分析
全參數微調(Full Parameter Fine-tuning)
傳統的全參數微調雖然效果最好,但對計算資源要求較高。
最新研究進展
- 任務自適應微調(Task-Adaptive Fine-Tuning):針對特定任務進行微調,提高應用準確性。
- 領域自適應微調(Domain-Adaptive Fine-Tuning):讓模型適應特定領域專業術語。
- 參數高效微調(Parameter-Efficient Fine-Tuning):利用 LoRA 降低計算成本,提高效率。
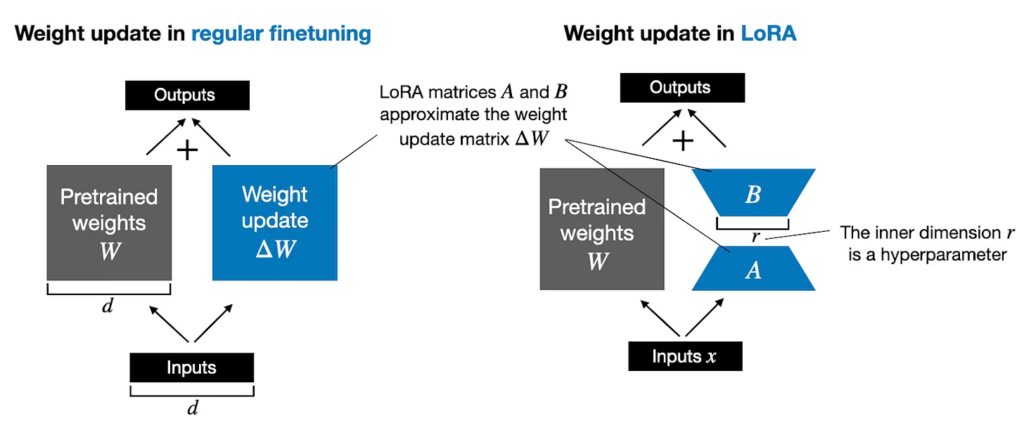
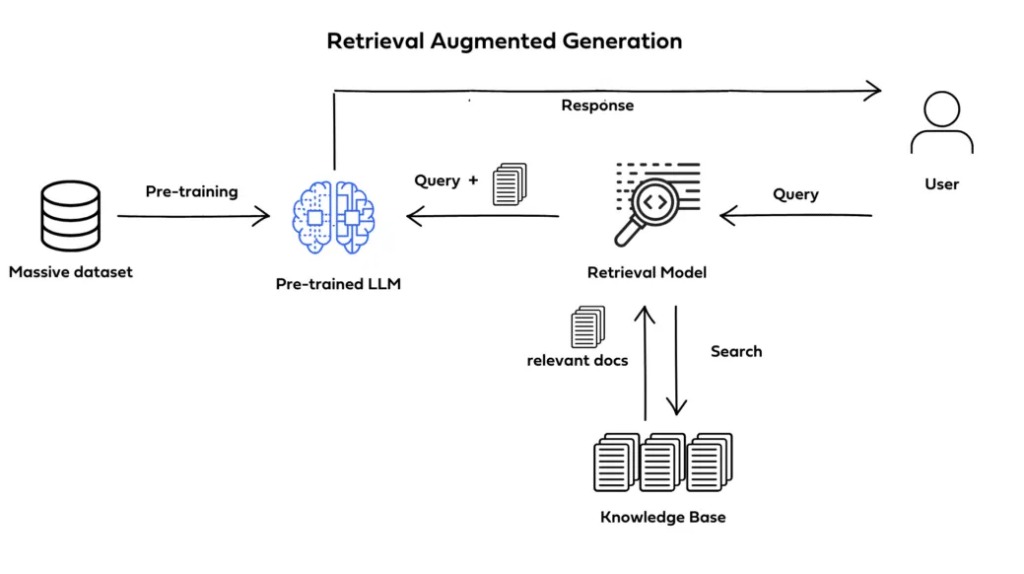
2. 檢索增強生成(RAG, Retrieval-Augmented Generation)
RAG 方法將 LLM 與外部知識庫(向量資料庫)結合,使其能在回答問題時即時檢索最新資訊。
- 適用場景:動態知識更新的系統,如法規諮詢、財經分析。
- 工具推薦:FAISS、Pinecone、Weaviate。
最新研究進展
- PIKE-RAG:透過多層次異構知識庫提升 LLM 在複雜工業場景中的推理能力。
- xRAG:提升多模態資料檢索與生成的效率。
- GraphRAG:利用知識圖譜增強語義檢索,提升準確性。

技術選擇與實踐建議
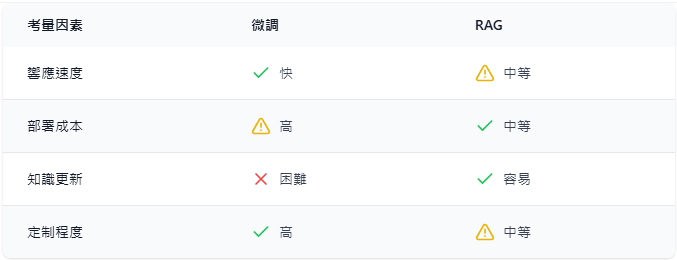
選擇微調還是 RAG,沒有標準答案,在實際應用中,往往需要結合兩種技術的優勢,關鍵在於:
- 了解業務需求
- 評估資源限制
- 考慮維護成本
- 權衡技術取捨

案例分析
案例 1:金融法規諮詢系統
某大型銀行希望開發內部法規諮詢系統,讓員工能透過對話界面快速查詢法規。
- 方法:
- 採用 RAG 方法,讓 LLM 即時檢索最新法規。
- 微調 GPT-4 來適應內部法規用語。
- 結果:
- 查詢法規時間減少 40%
- 降低合規風險
案例 2:醫療問診輔助系統
某醫院希望利用 LLM 輔助醫生進行診斷建議,提升診斷準確率。
- 方法:
- 微調 LLM 學習臨床案例。
- 搭配 提示工程 讓醫生輸入病症時獲得標準化建議。
- 結果:
- 診斷準確率提升 20%
- 降低診斷錯誤

結論
訓練 LLM 來打造企業內的專家系統,能夠大幅提升生產力與準確性。
關鍵成功因素
✅ 明確定義目標與範圍 ✅ 準備高品質專業數據 ✅ 選擇適合的訓練方法(微調、RAG) ✅ 持續測試與監控模型準確性
透過這些策略,企業可以打造專屬 LLM,提升業務效率、降低錯誤率,確保企業知識傳承,取得競爭優勢。
常見問題解答
Q: 微調和 RAG 可以同時使用嗎? A: 可以,許多企業實踐中都採用混合策略,針對不同類型的查詢使用不同的技術。
Q: 如何評估微調的效果? A: 可以從準確率、響應時間、資源消耗等多個維度進行評估,具體標準要根據實際應用場景來定。
