DeepSeek 是近年來備受矚目的大型語言模型(LLM),專為提升推理精準度、格式一致性與語言理解能力而設計。它在 Transformer 架構的基礎上,結合了 蒸餾技術(Knowledge Distillation)、強化學習(Reinforcement Learning, RL),以及 多層次獎勵機制,讓 AI 更加高效、準確且易於理解。
這篇文章將深入探討 DeepSeek 的技術架構、訓練方法,以及如何透過獎勵機制提升模型推理能力。
Key Insights
- 技術創新的多層次整合:DeepSeek 通過整合知識蒸餾、強化學習(RLHF)和思維鏈(CoT)等先進技術,創造了一個能夠進行複雜推理的完整 AI 系統,特別是其獨特的四層獎勵機制設計,為未來 AI 模型的訓練方法提供了新的範式。
- 語言理解的突破性進展:DeepSeek 在多語言處理方面實現了重大突破,特別是通過語言一致性獎勵機制解決了思維鏈推理中的語言混合問題,這為跨語言 AI 應用開闢了新的可能性。
- 實用性與可擴展性的平衡:通過創新的知識蒸餾技術,DeepSeek 成功實現了模型的輕量化,同時保持了強大的推理能力,這種平衡為企業級 AI 應用提供了實用的解決方案。
DeepSeek 簡介
DeepSeek 是一種專注於推理任務與邏輯推理的 大型語言模型(LLM, Large Language Model),其目標是透過高效學習技術與多層次獎勵機制,使 AI 更準確、更結構化、更易於理解。
DeepSeek 與 GPT-4、Llama 3、Claude 2 的比較
DeepSeek 相較於其他 LLM,具備以下特色:
- 增強推理能力(透過 CoT、RLHF 提升 AI 的邏輯能力)
- 多層次獎勵機制(確保模型回答格式統一且語言清晰)
- 專為企業應用與內部部署設計(類似 Mistral / Llama 3)

DeepSeek 核心架構
DeepSeek 主要基於 Transformer 架構(Decoder-Only),與 GPT-4、Llama 3 相似,並透過:
- 知識蒸餾(Knowledge Distillation)
- 強化學習(Reinforcement Learning)
- 推理獎勵機制(Reward Models)
- 格式優化與語言一致性調整
這些技術共同提升 DeepSeek 的表現,使其在推理、數學、語言理解等任務上更具優勢。
1. 知識蒸餾(Knowledge Distillation)
知識蒸餾是一種 壓縮與加速 LLM 的技術,透過 大模型(Teacher Model)訓練小模型(Student Model),讓小模型學習大模型的能力,同時保持高準確性。
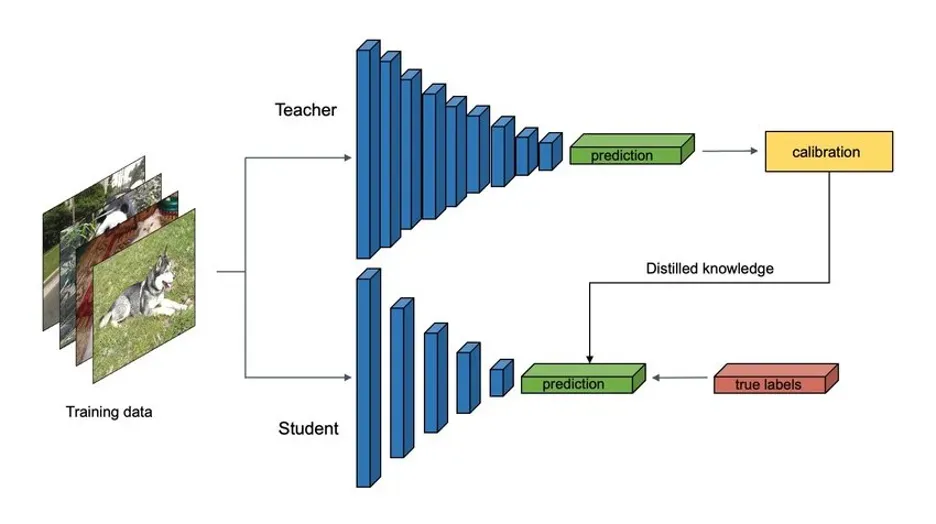
DeepSeek 如何應用知識蒸餾?
- 軟標籤學習(Soft Label Learning):
- 教師模型不僅提供正確答案,還提供「機率分佈」,讓學生模型學習答案的信心程度。
- 對比學習蒸餾(Contrastive Distillation):
- 學生模型不僅學習正確答案,也學習「為何其他選項錯誤」。
- 中間層對齊(Intermediate Feature Matching):
- 讓學生模型學習教師模型的「內部思考方式」,提升推理能力。
✅ 優勢
- 減少計算需求,使模型 更輕量化,適合企業內部部署。
- 提高推理準確度,確保模型學習最佳語言模式。
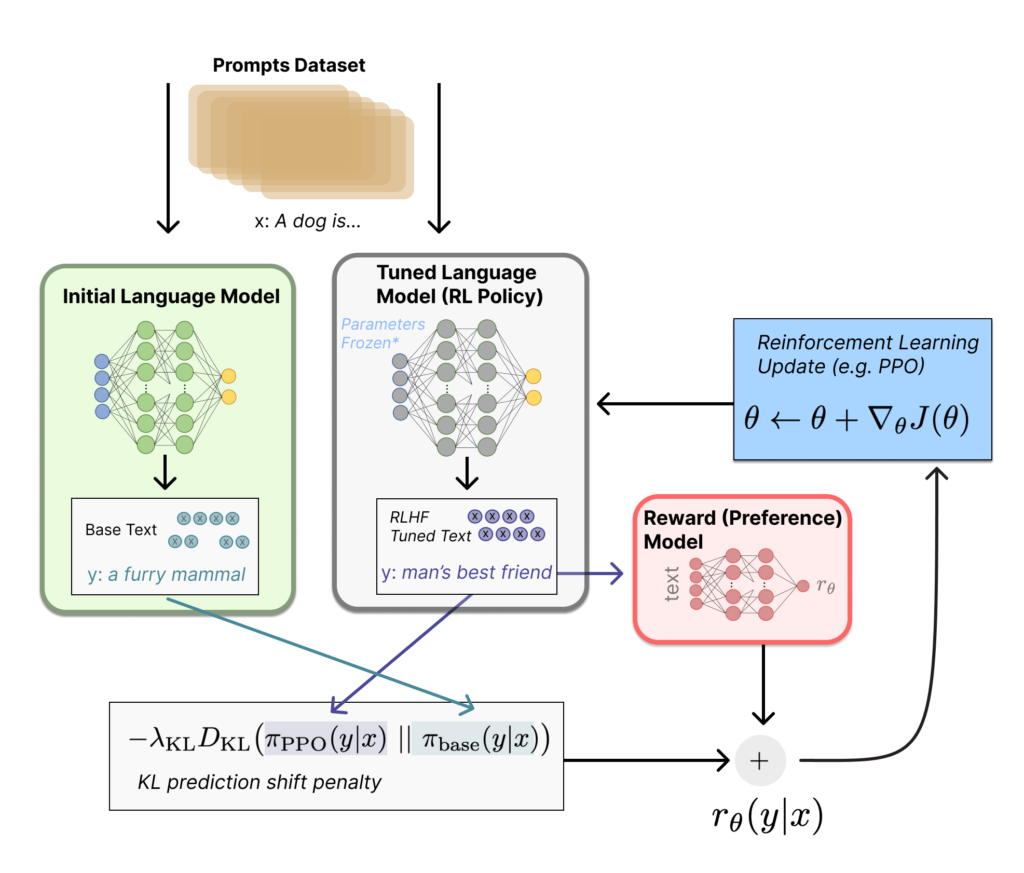
2. 強化學習與獎勵機制(RLHF)
DeepSeek 使用 RLHF(Reinforcement Learning from Human Feedback),並額外加入了 精準性獎勵、格式獎勵、語言一致性獎勵,來提升推理能力與可讀性。
3. 思維鏈(Chain of Thought, CoT)
研究(Wei et al., 2022)顯示,思維鏈(CoT)能有效提升 LLM 的推理能力。DeepSeek 透過 CoT,讓 AI 學習如何逐步拆解問題,並在回答前列出推理步驟。
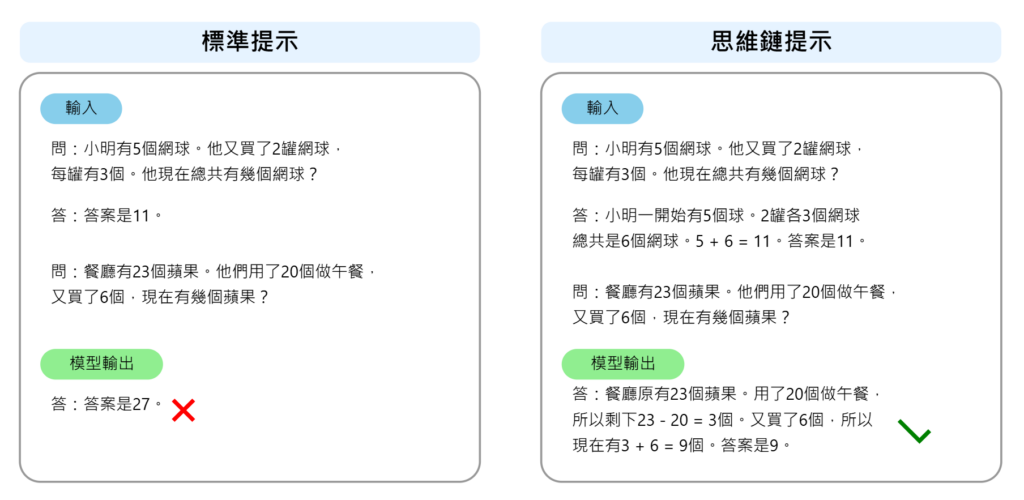
其優勢是讓 AI 更具邏輯性,適用於數學、邏輯推理、法律分析等高階任務。
4. DeepSeek 的獎勵機制
DeepSeek 透過以下獎勵機制來引導 AI 思考,使其更符合人類期望:
- 精準性獎勵(Accuracy Reward):提升 AI 在推理任務中的正確率,使其給出更準確的答案。
- 格式獎勵(Format Reward):規範 AI 的輸出格式,使推理過程更具結構性。運作方式為 DeepSeek 要求 AI 將推理過程置於
<think>和</think>標籤之間,確保輸出可讀性。 - 語言一致性獎勵(Language Consistency Reward):確保 AI 在多語言推理時保持語言一致性,避免混雜語言影響理解。

如何使用 DeepSeek?
DeepSeek 可應用於:
- 數學推理與邏輯分析
- 企業 AI 助手與自動化客服
- 法律與金融分析
- AI 內容生成與翻譯
使用方式
- 微調模型(Fine-Tuning):
- 適用於企業內部應用,如 AI 客服、法律 AI 助理。
- RAG(檢索增強生成)+ DeepSeek:
- 讓 DeepSeek 連接即時資料庫,提高回答準確度。

DeepSeek 的未來發展
- 支援多模態 AI(處理圖像、音訊等)
- 進一步優化 RAG 技術
- 增強 MoE(Mixture of Experts)技術,降低計算成本

結論
DeepSeek 透過 知識蒸餾、強化學習、格式獎勵、語言一致性獎勵、思維鏈技術,顯著提升了 推理準確性、語言統一性、可讀性,使 AI 更精確、更結構化、更易於理解。

常見問題解答
Q: 如何優化 DeepSeek AI 的使用效果? A: 通過合理的提示詞設計、參數調整和資源配置來優化性能。

Reference
- Wei, J., et al. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS.
- OpenAI (2023). GPT-4 Technical Report.
- DeepSeek AI (2024). Official Model Documentation.
