AI 如何理解語言?LLM 的誕生
想像一下,你問 ChatGPT:「如何提升寫作技巧?」AI 能夠理解你的問題,並且給出結構良好的建議。這背後的技術就是 大型語言模型(LLM, Large Language Model)。
LLM 是一種透過深度學習和自然語言處理(NLP)來理解和生成語言的 AI 模型。這類模型的應用範圍廣泛,從聊天機器人(ChatGPT、Claude)、內容生成(Jasper AI)、翻譯(DeepL)到程式碼輔助(GitHub Copilot),無所不在。
但你知道嗎?目前 LLM 還有許多侷限,例如 高昂的運行成本、幻覺(Hallucination)問題,以及知識更新受限。這篇文章將深入剖析 LLM 的原理、技術發展與挑戰
Insights
- LLM 的核心突破在於 Transformer 架構的自注意力機制,這使 AI 首次能夠真正理解語言的上下文關係,並實現自然的人機對話,徹底改變了 NLP 領域。
- 當前 LLM 技術發展呈現雙軌並行趨勢:一邊是像 GPT-4、Claude 等追求極致性能的大模型,另一邊是如 Mistral、DeepSeek 等通過知識蒸餾實現高效輕量化的模型,為不同應用場景提供選擇。
- LLM 的未來發展重點已從單純追求模型規模轉向解決實際應用問題,包括通過 RAG 技術提升準確性、發展多模態能力擴展應用範圍,以及加強模型可解釋性來應對倫理和監管挑戰。
什麼是大型語言模型(LLM)?為什麼如此重要?
LLM 之所以能夠「思考」,關鍵在於 Transformer —— 由 Google 在 2017 年提出的革命性 AI 架構(論文:《Attention Is All You Need》)。透過訓練大量文本數據來學習語言模式,能夠執行對話、內容生成、程式碼撰寫等多種應用。隨著 AI 進步,LLM 已成為企業、教育、醫療、金融等產業的核心技術。在進入技術細節之前,讓我們先理解 LLM 的重要性:
- 生產力的提升:從程式開發到內容創作,全面提升工作效率
- 自然語言理解的突破:首次實現真正自然的人機對話
- 知識獲取的革新:將海量信息轉化為可即時應用的知識

LLM 的核心技術與運作方式
1. Transformer AI 語言理解的引擎 – 架構說明
LLM 主要基於 Transformer(Google 在 2017 年提出)架構,它透過 自注意力機制(Self-Attention) 來理解語言的關係。相比傳統的 RNN/LSTM,Transformer 具備更強的並行處理能力,使得 LLM 在處理長文本時更加高效,能夠學習更深層次的語言結構。
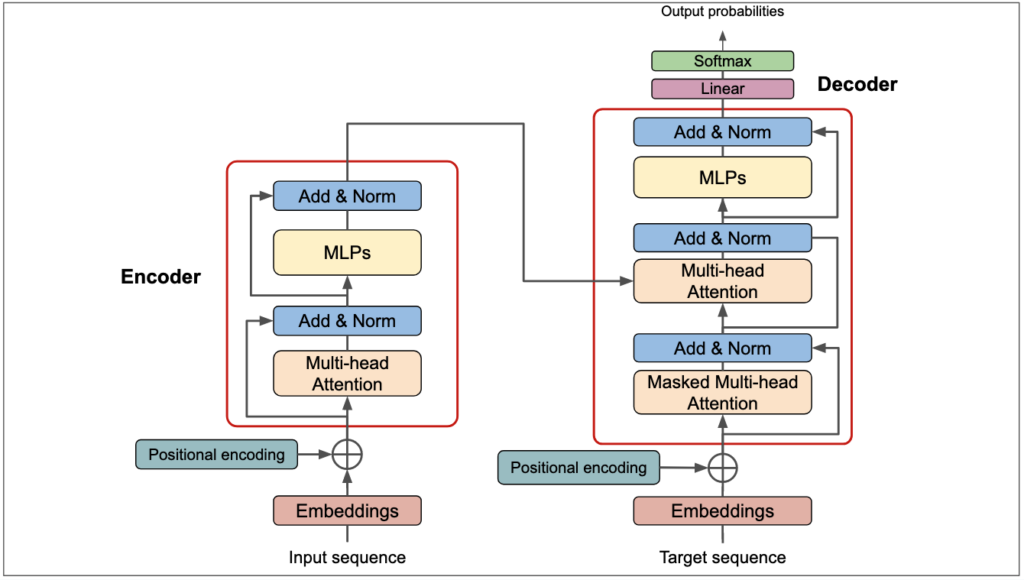
A. 自注意力機制(Self-Attention):全方位的語言理解
就像人類閱讀時會關注句子中的關鍵詞一樣,自注意力機制允許模型:
- 同時處理句子中的所有詞語
- 理解詞語之間的複雜關係
- 捕捉長距離的語義依賴
例如在分析「蘋果公司發布新產品」這句話時:
- 模型會理解「蘋果」在這裡指的是公司而非水果
- 通過上下文關係理解「發布」的主體是「蘋果公司」
- 將「新產品」與「蘋果公司」和「發布」關聯起來
B. 位置編碼(Multi-Head Attention):語序的數學表達
語言中詞序至關重要,位置編碼巧妙地解決了這個問題:
- 使用數學函數編碼位置信息
- 保持詞序的同時支持並行處理
- 實現任意長度文本的處理
C. 編碼器-解碼器:理解與生成的完美結合
就像人類的思考和表達過程:
- 編碼器負責「理解」輸入信息
- 解碼器負責「組織」並「表達」想法
- 兩者通過注意力機制緊密協作
2. 事前訓練(Pretraining)與微調(Fine-tuning)
LLM 訓練主要分為兩個階段:
- 事前訓練:使用海量的網頁、書籍、新聞等資料,學習語言結構與基本知識。
- 微調與強化學習(RLHF, Reinforcement Learning from Human Feedback):透過人類標註數據來調整 LLM 的回答方式,提高模型的準確度與可用性。
OpenAI 訓練 GPT-4 時,使用了 RLHF(Reinforcement Learning from Human Feedback)技術,透過人類反饋來提升 AI 回答的準確性與道德性。
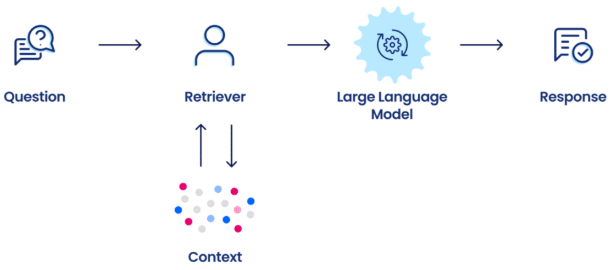
3. 知識檢索增強(RAG)- 減少幻覺
RAG(Retrieval-Augmented Generation)是一種讓 LLM 查詢外部知識庫的技術,適用於需要最新資訊的應用,如醫療、法律等領域。透過 RAG,LLM 能夠即時檢索並結合最新數據,提高準確性並減少幻覺問題。
4. 量化技術(Quantization)與輕量化、高效能的 LLM
- 量化技術透過 4-bit 或 8-bit 模型壓縮來降低 LLM 記憶體需求,使其能夠在較小的設備上運行。這項技術讓企業能夠在有限硬體資源下部署 LLM,提升可及性。
- DeepSeek、Mistral 透過知識蒸餾(Knowledge Distillation) 讓模型變小但保持強大能力

目前主流的 LLM 模型與比較
目前 LLM 領域競爭激烈,以下是幾個主流的模型與它們的特點:
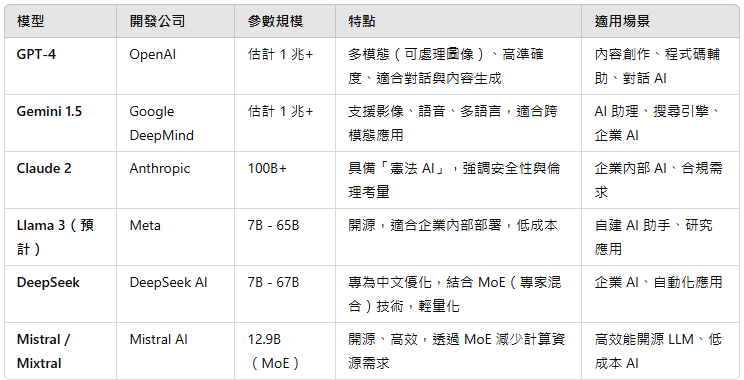
些模型各有優勢,企業與開發者應根據需求選擇適合的 LLM,例如:
- 高效能、封閉 API: 適合企業應用,如 GPT-4、Gemini
- 可內部部署、開源: 適合自建 AI,如 Llama 3、DeepSeek、Mistral

LLM 的未來發展趨勢
- 更高效的模型架構
- 開發 更小但同樣強大的 LLM,如 Mixture of Experts(MoE) 技術,能夠提高運算效率,降低運行成本。
- DeepSeek 和 Mistral 透過蒸餾技術來減少模型參數,同時保留強大效能。
- 強化檢索增強(Advanced RAG)
- 下一代 LLM 將更精細地結合檢索機制,提供更準確的資訊,並減少幻覺問題。
- 增強多模態能力(Multimodal AI)
- 例如 OpenAI 的 GPT-4V、Google Gemini,這些 LLM 可以處理不僅限於文字的資訊,還能解讀圖片、音訊,甚至影片,提升 AI 的應用範圍。
- LLM 的可解釋性提升
- LLM 仍然面臨可解釋性問題,即 為何模型會生成特定答案? 許多研究正致力於讓 LLM 更具透明度
- 倫理挑戰如 偏見(Bias) 和 錯誤信息(Misinformation) 也是 LLM 需要克服的問題。AI 監管與道德標準的建立,將是未來 LLM 發展的重要趨勢。

結論:LLM 的未來影響與挑戰
LLM 正在重塑各行各業,從客服自動化、醫療診斷到法律輔助,應用範圍廣泛。然而,它仍面臨高計算成本、數據隱私、幻覺問題等挑戰。未來,隨著技術的進步,LLM 將變得更高效、更輕量化,也將適應新的監管要求,成為更具可解釋性與可靠性的 AI 工具。
在 AI 迅速發展的時代,你如何看待 LLM 的未來?你的企業或產業如何應用這項技術?歡迎留言交流你的見解。
