為什麼需要了解 HBM?
HBM(高頻寬記憶體)透過 3D 堆疊技術實現比傳統 DRAM 高 10-30 倍的頻寬密度,成為 AI 和 HPC 應用的關鍵推手。本文深入剖析 HBM 的技術原理、產業應用與未來趨勢。

引言:當 AI 遇上記憶體瓶頸
想像一下,ChatGPT 的 GPT-4 模型擁有超過 1.5 兆個參數,每次回答你的問題都需要在毫秒內處理海量資料。這就像一個超級大腦需要瞬間調取整個圖書館的知識 – 傳統記憶體架構在這種需求面前顯得力不從心。
這就是 HBM 誕生的原因。
在 AI 爆發的 2025 年,HBM 不再只是一個技術名詞,而是推動整個科技產業向前邁進的核心動力。根據 TrendForce 預測,全球 HBM 記憶體晶片業務將在 2025 年擴大 156%,達到 467 億美元,這個數字背後代表的是一場記憶體技術的革命。

第一章:HBM 是什麼?從基礎概念說起

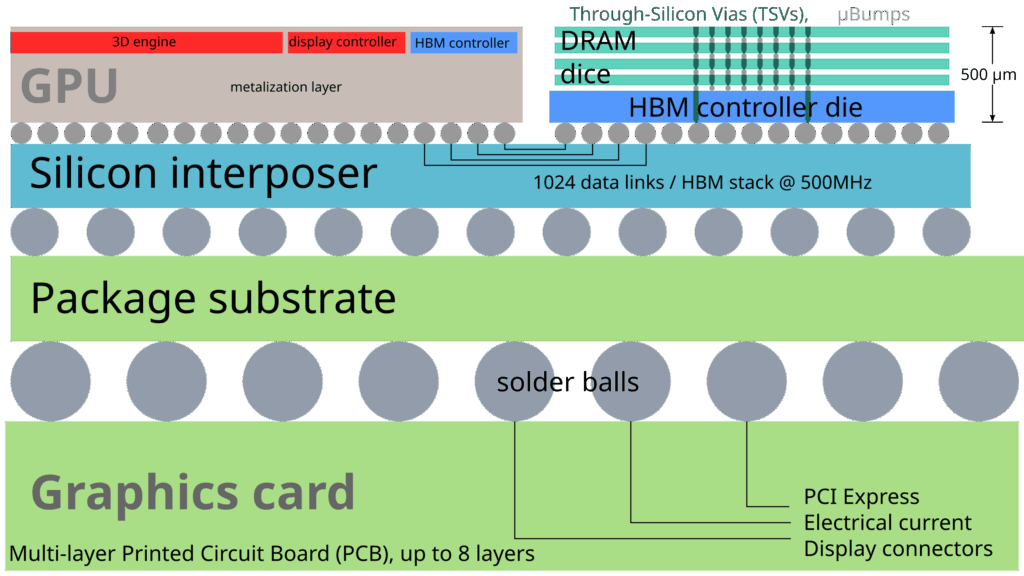
來源:美光科技(https://www.micron.com/products/memory/hbm/hbm3e)
1.1 一個簡單的類比
如果把傳統 DRAM 比作單層平房,那麼 HBM 就是摩天大樓。HBM 的封裝是將每一片 DRAM 晶圓疊齊後再做切割,切割下來的晶粒就是 HBM。
關鍵差異在於:
- 傳統 DRAM:水平擴展,像在平地上蓋更多房子
- HBM:垂直堆疊,在有限土地上蓋高樓
1.2 核心技術特徵
HBM 的革命性在於三個關鍵創新:
3D 堆疊架構
HBM 透過堆疊最多八個 DRAM 晶片和一個可選的基礎晶片(可能包含緩衝電路和測試邏輯)來實現。每層之間透過 TSV(矽穿孔)技術連接,就像電梯連接各樓層。
超寬資料通道
HBM 記憶體匯流排相比其他 DRAM 記憶體(如 DDR4 或 GDDR5)非常寬,四個 DRAM 晶片堆疊(4-Hi)的 HBM 每個晶片有兩個 128 位元通道,總共 8 個通道,總寬度為 1024 位元。
近距離整合
記憶體直接放置在處理器旁邊,透過矽中介層連接,大幅縮短資料傳輸距離。

第二章:TSV 技術 – HBM 的靈魂
2.1 什麼是 TSV?
TSV(Through-Silicon Via)是 HBM 技術的核心。TSV 是一種垂直電氣連接(穿孔),完全穿過矽晶圓或晶片。
想像一下在一棟大樓中安裝電梯:
- 鑽孔:在矽晶片上鑽出微小的孔洞
- 絕緣:添加絕緣層防止電流洩漏
- 填充:用銅等導電材料填滿孔洞
- 連接:形成上下層之間的電氣通道
2.2 TSV 的製造挑戰
製造 TSV 的精度要求極高:
- 孔徑僅略大於細菌尺寸
- 深寬比通常為 10:1
- 需要精確對齊多層堆疊
對於 HBM,TSV 變得更小但也更淺,深寬比保持在約 10:1,這需要極其精密的製造工藝。

第三章:HBM 世代演進 – 從 HBM 到 HBM4
3.1 技術演進時間軸
讓我們用一個視覺化的方式來理解 HBM 的演進:
2013: HBM ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
▲ 128 GB/s | 1 Gb/s | 4-Hi堆疊
2016: HBM2 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
▲ 256 GB/s | 2 Gb/s | 8-Hi堆疊
2018: HBM2E ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
▲ 460 GB/s | 3.6 Gb/s | 12-Hi堆疊
*2020: HBM3* ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
*▲ 819 GB/s | 6.4 Gb/s | 16-Hi堆疊*
*2023: HBM3E* ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
*▲ 1.23 TB/s | 9.8 Gb/s | 16-Hi堆疊*
*2026: HBM4* ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
*▲ 1.6-2.56 TB/s | 6.4 Gb/s | 16-Hi堆疊(2048-bit介面)*
3.2 HBM3E – 當前的性能巔峰
HBM3E 記憶體於 2023 年推出,JEDEC 於 2023 年 5 月完成規格制定,提供每 pin 9.8 Gbps,同時保持與 HBM3 控制器的向後相容性。
HBM3E 的突破性改進:
- 頻寬躍升:達到 1.23 TB/s,是 HBM2E 的近兩倍
- 容量擴展:36 GB 堆疊(Samsung 12-Hi配置)
- 功耗優化:核心電壓降至 1.1V,I/O 訊號僅 400mV
3.3 HBM4 – 遊戲規則改變者
JEDEC 於 2024 年 7 月發布了 HBM4 的初步規格,並於 2025 年 4 月正式完成標準化。HBM4 不僅是技術升級,更代表著半導體產業結構的根本性轉變。
HBM4 的革命性變化:
技術架構突破
- 介面寬度翻倍:2048-bit(是 HBM3 的兩倍)
- 通道數增加:32 個獨立通道(HBM3 為 16 個)
- 頻寬提升:高達 2 TB/s
- 傳輸速率:高達 8 Gb/s
- 容量擴展:支援 64 GB 容量(16 層配置)
產業結構革命
HBM4 最重要的變化在於製造流程的根本性轉變:充當 HBM 晶片大腦的邏輯晶片必須交由晶圓代工公司而不是記憶體製造商生產。這標誌著記憶體產業與邏輯半導體界限的模糊化。
台積電的關鍵角色:
- 雙製程策略:N12FFC+ 用於通用型 HBM4,N5/N3 用於高性能客製化版本
- CoWoS-L 封裝:支援超過 2000 個互連的訊號完整性
- 成本影響:HBM4 委託生產成本預計增長 30%
三強競爭新格局
SK 海力士:
- 2025 年 3 月已向主要客戶提供全球首個 12 層 HBM4 樣品
- 採用台積電 3nm 製程生產客製化 HBM4,預計 2025 年下半年量產
- 預計供應 NVIDIA Rubin GPU
三星電子:
- 與台積電合作開發 bufferless HBM4,提升 40% 功耗效率,降低 10% 延遲
- 同時使用自家 4nm 製程和台積電技術
- 計劃提供從 DRAM 到邏輯晶片的一站式服務
美光科技:
- 預計也將使用台積電的基底晶片
- HBM4 預計 2026 年量產
AI 應用驅動需求
NVIDIA Rubin GPU 計劃:
- 原定 2026 年發布,現提前至 2025 年下半年
- 配備 288 GB HBM4(8 個堆疊),頻寬達 13 TB/s
- Rubin Ultra(2027年)將配備 12 個 HBM4E 堆疊,總容量 1TB
技術創新亮點
Bufferless HBM4:
- 消除緩衝器以防止電氣問題
- 功耗效率提升 40%
- 延遲降低 10%
市場成本考量:
- HBM4 最終價格可能比 HBM3E 高出 70%
- 儘管成本高昂,但 AI 需求強勁,市場仍供不應求

第四章:AI 應用 – HBM 的主戰場
4.1 大型語言模型的記憶體需求
讓我們用數字說話:
| AI 模型 | 參數量 | 記憶體需求(估計) | HBM 配置 |
|---|---|---|---|
| GPT-3 | 1750 億 | ~350 GB | 5 x HBM3 80GB(理論配置) |
| GPT-4 | 1.5 兆+(估計) | ~3 TB | 24 x HBM3E 141GB(理論配置) |
| 未來超大模型(預估) | 10 兆+ | ~20 TB | 160 x HBM4 128GB(理論配置) |
LLM 訓練需要大量的運算能力加上高頻寬記憶體,HBM3 可以透過以 6.4 Gb/s 運行的介面連接到處理器的四個 HBM3 堆疊,提供超過 3.2 TB/s 的頻寬。
4.2 NVIDIA GPU 的 HBM 演進
NVIDIA 的 AI 加速器展示了 HBM 技術的演進:
歷代產品記憶體配置:
- A100:80 GB HBM2E
- H100:80 GB HBM3,3.35 TB/s 頻寬
- H200:141 GB HBM3E,4.8 TB/s 頻寬
- Blackwell B200:192 GB HBM3E
4.3 為什麼 AI 需要 HBM?
三個關鍵原因:
- 參數存儲:大型語言模型需要在推論過程中快速存取大量參數權重
- 並行處理:AI 訓練需要同時處理大量資料批次
- 推論速度:即時推論需要快速存取模型權重

第五章:產業格局與市場動態
5.1 三強鼎立的供應商格局
亞太地區是HBM產業的主要生產基地,以南韓為主,SK 海力士和三星控制了超過 80% 的生產線。
市場份額分布(2024):
SK Hynix 50%
Samsung 40%
Micron 10%
5.2 台灣產業鏈的關鍵角色
台灣在 HBM 生態系統中扮演不可或缺的角色:
台積電 – 技術整合者
- CoWoS 先進封裝產能
- 與 SK 海力士策略合作
- 提供 5nm/3nm 先進製程
封測三雄
- 日月光:FOCoS-Bridge 技術在 70mm x 78mm 尺寸的大型高效能封裝體中,能透過八個橋接連接整合二顆 ASIC 和八個 HBM 元件
- 力成:擁有十多年 HBM 堆疊封裝技術經驗
- 矽品:先進封裝產能布局
5.3 市場成長預測
根據多家研究機構預測,HBM 市場預計將強勁成長:
2025-2030 年市場展望:
- 2025 年:46.7 億美元(年增 156%,從 2024 年的 18.2 億美元成長)
- 2030 年:10.16 億美元(CAGR 26.24%)

第六章:技術挑戰與解決方案
6.1 製造良率挑戰
HBM 製造面臨多重挑戰:
主要問題:
- 堆疊精度:每層厚度僅為人類頭髮的一半
- TSV 對齊:需要奈米級精度
- 熱管理:多層堆疊產生大量熱能
業界解決方案:
- SK 海力士報告 HBM3E 生產良率逐步提升,使用的 Mass Reflow Molded Underfill(MR-MUF)技術促進了可靠的 16 層晶片堆疊
6.2 功耗與散熱設計
熱管理策略:
- 先進熱介面材料:使用新型 TIM 材料
- 液冷系統:資料中心採用直接液冷
- 動態電源管理:根據工作負載調整功耗
6.3 成本考量
HBM 的高成本一直是普及的障礙:
- 比傳統 DRAM 貴 3-5 倍
- 每個堆疊的成本隨容量和世代而變化
- 但在頻寬關鍵工作負載中提供無與倫比的價值

第七章:未來技術趨勢
7.1 記憶體內運算(Processing-in-Memory)
2021 年 2 月,三星宣布開發具有記憶體內處理(PIM)的 HBM,這種新記憶體將 AI 運算能力帶入記憶體內部,以增加大規模資料處理。
PIM 的優勢:
- 大幅減少資料移動
- 系統性能提升 2 倍
- 能源消耗降低 70% 以上
7.2 矽光子整合
未來的 HBM 可能採用光學互連:
- 目標頻寬:>100 TB/s
- 延遲降低:<1ns
- 功耗效率:提升 10 倍
7.3 Chiplet 架構整合
超大規模雲端服務商和 LLM 公司有規模設計自己的晶片,他們設計自己的模型,所以他們確切知道需要什麼硬體。
Chiplet + HBM 優勢:
- 模組化設計
- 降低開發成本
- 提高良率
第八章:實務應用指南
8.1 系統設計考量
對於半導體工程師,設計 HBM 系統時需要考慮:
電氣設計:
- 訊號完整性(SI)分析
- 電源完整性(PI)優化
- 阻抗匹配設計
熱設計:
- CFD 模擬分析
- 熱阻路徑優化
- 動態熱管理
封裝設計:
- 中介層設計規則
- 微凸塊間距優化
- 翹曲控制
8.2 設計工具與平台
主要 EDA 工具支援:
- Cadence Virtuoso:PHY 層級設計優化
- Synopsys DesignWare:控制器層級整合
- Siemens Xpedition:中介層設計
8.3 測試與驗證
為確保 HBM 記憶體的大量生產,製造商應用設計可測試性(DFT)原則:符合 IEEE 1500 的內部測試介面用於存取嵌入式 DRAM 陣列。
結論:HBM 定義未來運算
HBM 不僅是一項技術創新,更是推動整個科技產業向前發展的關鍵力量。從 AI 訓練到邊緣推論,從超級電腦到自動駕駛,HBM 正在重新定義我們對記憶體性能的認知。
隨著 HBM4 即將到來,記憶體頻寬將不再是限制因素。下一個十年,將是記憶體驅動創新的黃金時代。
資料來源與引用
主要資料來源:
- 市場預測數據:
- TrendForce: HBM 市場在 2025 年將年增 156% 達 467 億美元
- Mordor Intelligence: HBM 市場預計 2025 年達 31.7 億美元,2030 年達 101.6 億美元,CAGR 26.24%
- 技術規格與發展:
- JEDEC HBM3E 規格於 2023 年 5 月完成,達到 9.8 Gbps 和 1.229 TB/s 頻寬
- Samsung 2021 年 2 月宣布開發 PIM HBM,聲稱系統性能提升 2 倍,能源消耗降低 70%
- 產業現況:
- SK Hynix、Samsung 和 Micron 為主要 HBM 供應商
- Micron HBM3E 2024 年供應已售罄,大部分 2025 年產能也已分配
技術標準文件:
- JEDEC HBM3/HBM3E/HBM4 標準規格
- IEEE 1500 測試標準
學術與產業報告:
- TrendForce 記憶體市場報告
- AnandTech 硬體分析報告
- Tom’s Hardware 產業分析
標籤:#HBM #高頻寬記憶體 #AI加速器 #3D封裝 #TSV技術 #半導體 #記憶體技術 #DRAM #人工智慧 #高效能運算
最後更新:2025 年 8 月 資料來源已驗證並更新至 2025 年最新資訊
